Build a Disciplined Data Science Team
Download the Whitepaper

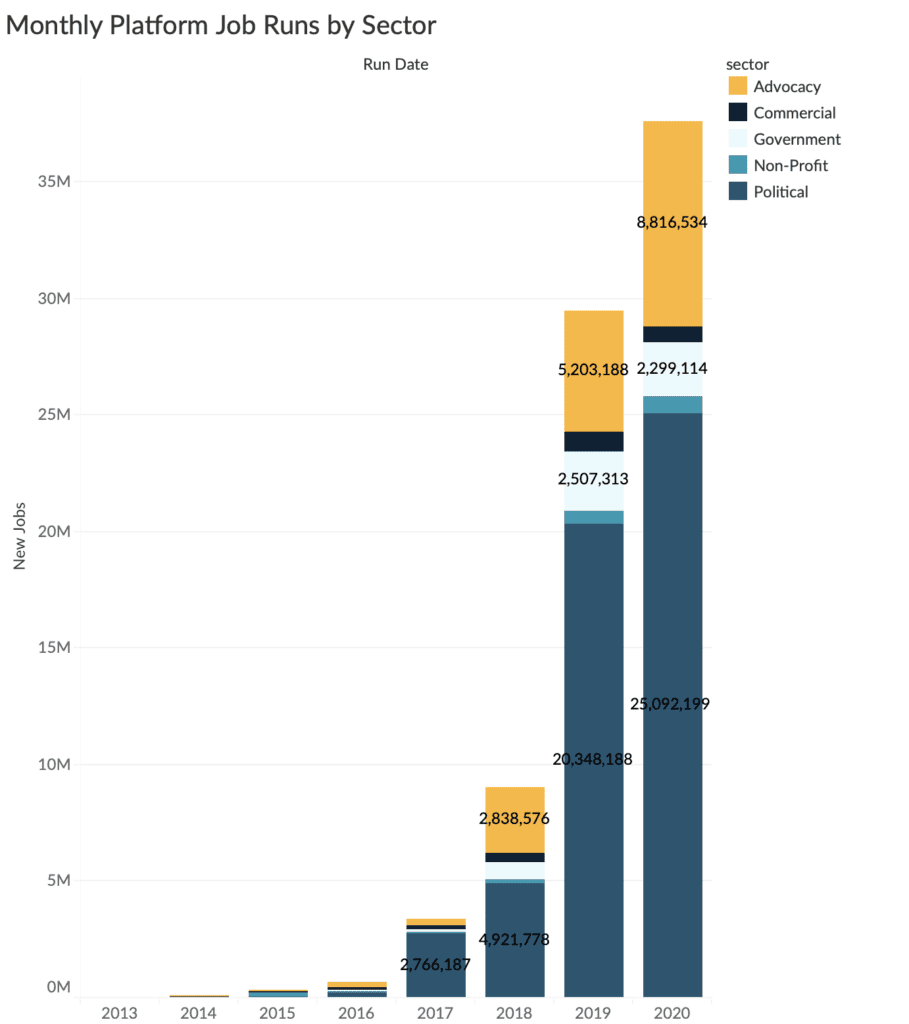
As the 2020 U.S. election cycle hit overdrive, demand on Civis Analytics’ systems reached historic levels, resulting from a sharp increase in jobs — executable tasks in Civis Platform such as importing data, building models, running scripts, etc. — during the runup to key campaign moments like the Iowa Caucuses, Super Tuesday, and the Democratic presidential primary debates.
As the graphic below illustrates, Civis experienced a 400 percent increase in jobs run by the political sector between 2018 and 2019, topping the 20 million mark; in 2020, that number surged to more than 25 million.
The sheer volume of demand forced us to rethink some of our core systems to ensure more stable, reliable products throughout the presidential race. A pivotal component of that effort is a service we call Sniffer.
Sniffer is Civis’s internal Kubernetes state management service. It informs clients of state changes to various Civis workloads which users run on Civis Platform. These workloads include Jupyter notebooks, web applications (such as Shiny Apps), and ad-hoc scripts (also referred to as “jobs”).
Workloads exist in differing states, such as “Succeeded,” “Failed,” “Running,” “Queued,” and “Cancelled.” For example, when a user kicks off a job, it progresses from Queued to Running, and then to Succeeded or Failed.
All of these workloads run as Docker containers in our Kubernetes Cluster: Sniffer watches the Kubernetes API for state changes, and communicates them to Civis Platform so that the state of each workload is visible to users.
Accurately knowing the state of each workload is necessary for our clients to feel confident that our systems are up and running. This accuracy is even more crucial for clients when they run Civis Workflows (multiple workloads connected in a complex processing network). If a client’s job within a workflow fails to update — say, from Running to Succeeded — it can hold up the rest of the workflow.
We initially wrote Sniffer in Python, but faced three critical issues: latency, reliability, and observability.
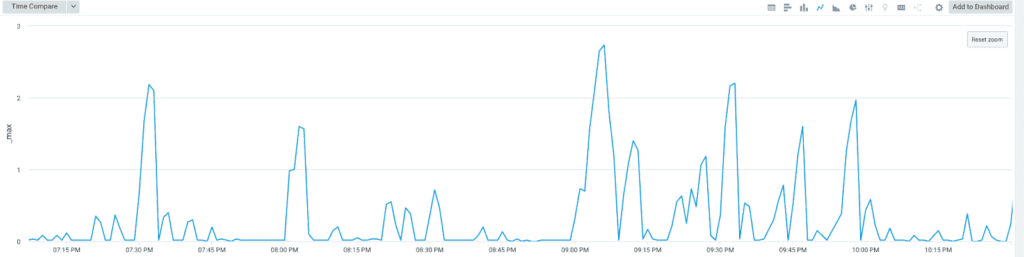
In terms of latency, Python Sniffer only processed one state change at a time, which resulted in long wait times to see state changes reflected in Platform. As you can see below, latency could reach more than two minutes during everyday use (the X axis shows time and the Y axis shows processing time in minutes):
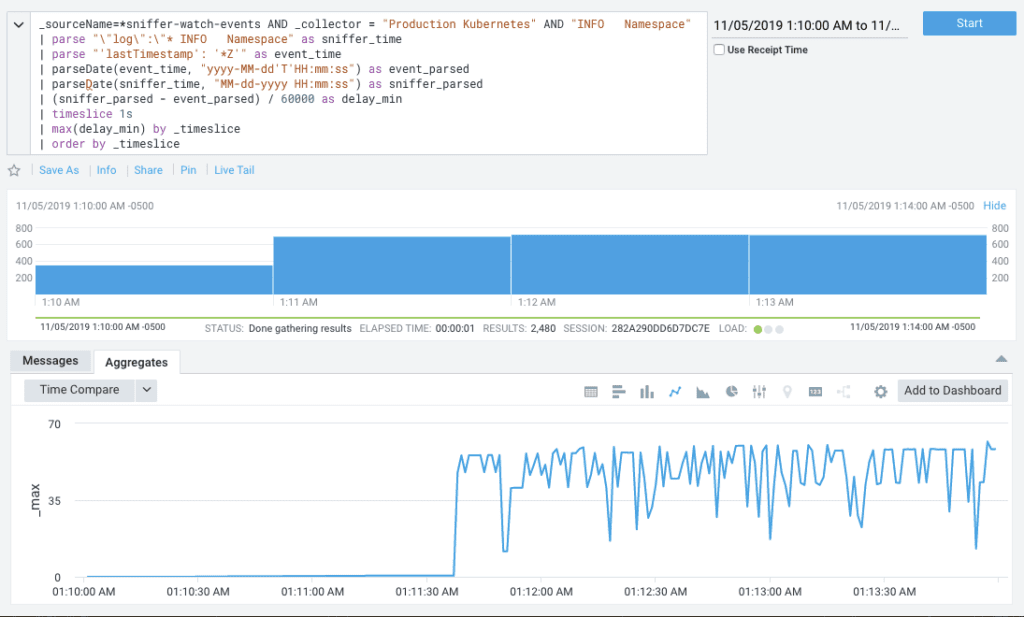
Latency would increase significantly during high-load situations, impacting every Civis Platform user. Sometimes, jobs would appear to have been running for extraordinarily long periods of time, despite already reaching completion. Below is a chart showing latency during a high-load situation: the X axis shows time, the Y axis shows average processing time in minutes, and as you can see, average latency jumps up to roughly 40 minutes.
In addition, Python Sniffer would unexpectedly go down and drop state events for unknown reasons, requiring the Civis support team to manually resolve state changes for clients. We tried to resolve the errors with different try/except statements, but it felt like a game of Whack-a-Mole.
As for observability, we lacked key metrics needed to monitor Python Sniffer’s performance. Specifically, we had no visibility into event throughput, the number of events being dropped, or how many events were queued up.
The problems with Python Sniffer were significant but solvable. The main design paradigm Python Sniffer followed was well defined in Kubernetes Land as Controllers, which at a high level continuously try to take a Kubernetes cluster from its current state to a desired state. In Sniffer’s case, it was trying to take Civis Platform from its current state to the desired state via state changes happening in Kubernetes.
Because the redesigned Sniffer isn’t much different from how internal Kubernetes Controllers are written, this section will focus on laying out the basic design of a Kubernetes controller via Go client.
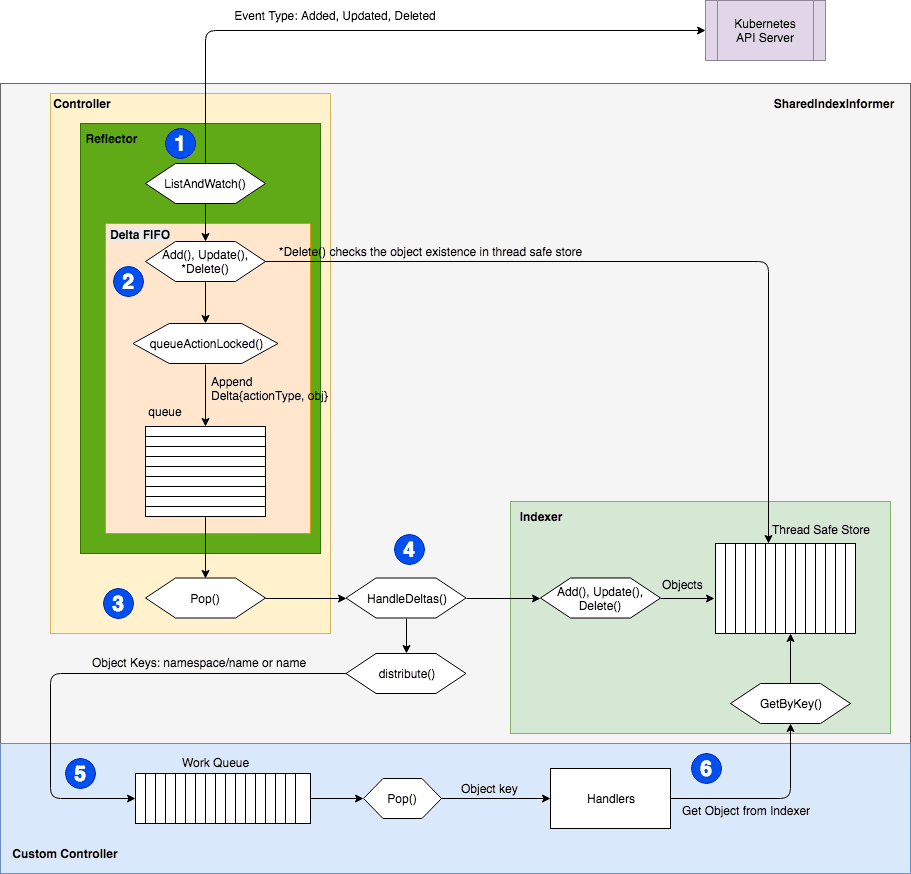
The graphic above (sourced from ITNEXT) depicts the data flow of state changes through the Go client’s Controller architecture. At a high level, there are four components that developers should understand:
Ultimately, the rewrite was a huge success. Go Sniffer solved our three critical problems:
Latency. Go Sniffer significantly outperformed Python Sniffer, processing state changes in one second or less on average (most of this time is spent “calling out” to update client-facing systems about the change). The graphic below depicts in terms of seconds the average overall processing latency for K8s events.
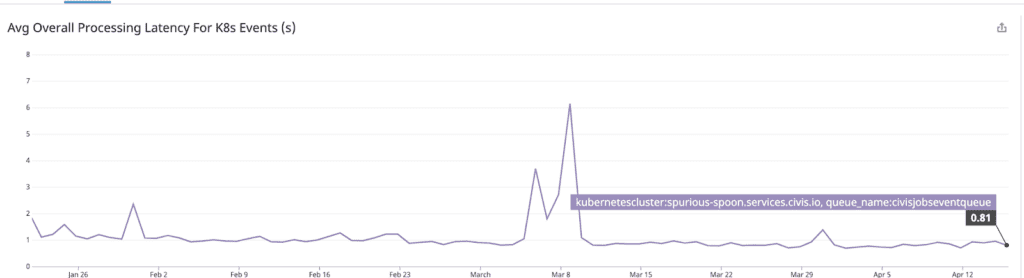
Even better, Go Sniffer maintained this latency profile through many high-load situations, giving us the consistency the Python implementation lacked. For example, the refactor was deployed in time for heavy traffic days for political clients including the Iowa Caucuses and Super Tuesday: during these periods, the Go implementation continued processing state changes in one second or less.
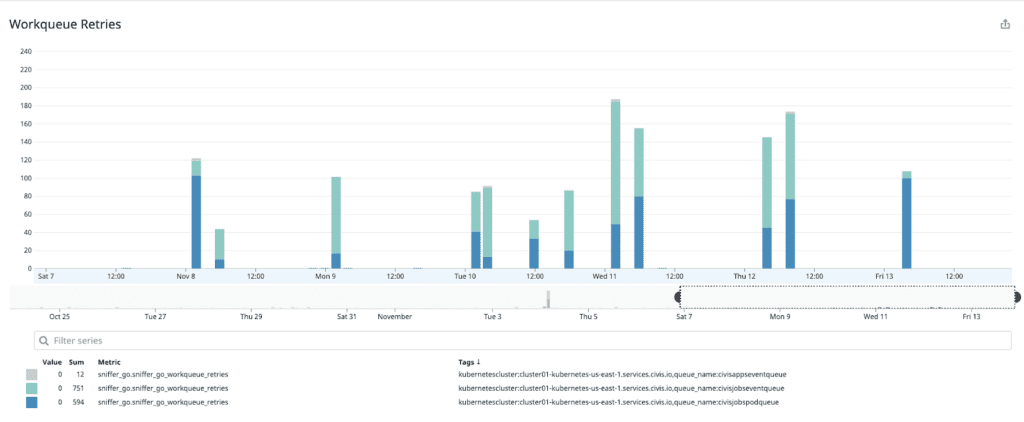
Reliability. The Go version didn’t restart intermittently like the Python version; in fact, it never died unless we initiated a redeploy. We also were able to track whether the Go version was dropping any state changes and leveraging its retry functionality. Anecdotally, we stopped receiving support tickets from users asking why their workloads were not updating. The graphic below depicts Workqueue retries for all Workqueues Sniffer runs.
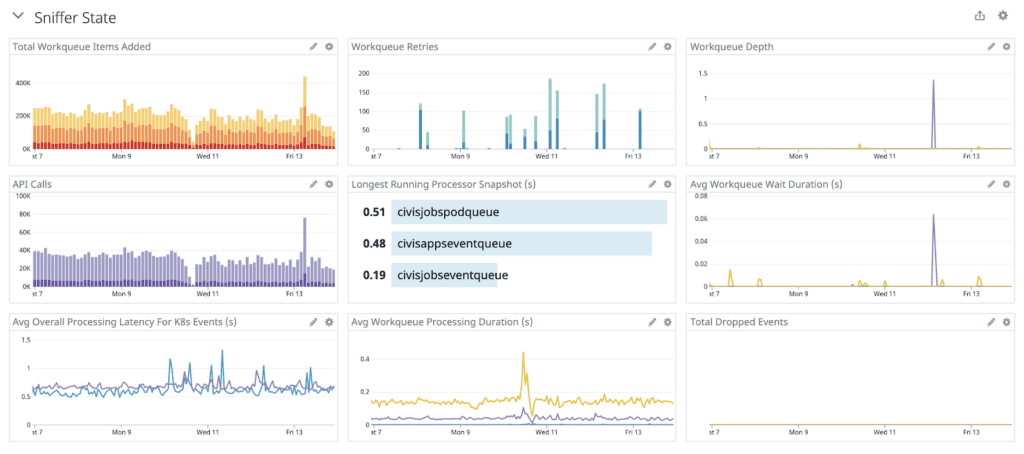
Observability. We had reliable metrics, thanks in part to the built-in metrics the Go client generates for us. We’ve also added our own custom metrics to enhance our understanding of what Sniffer is doing. We rely on critical metrics including throughput, processing latency, number of retries, and number of dropped state changes, and as we do for other services, we built a dashboard in Datadog to view these metrics (see below).
Rewriting Sniffer with Golang and the Kubernetes Go client was the right decision. We were able to successfully deploy Go Sniffer in time for the beginning of the Democratic presidential primaries, which allowed us to weather the heavy load the various political campaigns and progressive organizations put on Civis Platform during the early months of the 2020 primary season.
Our Go implementation of Sniffer continues to provide immense value through the Presidential campaign and into the present day. As Civis’s clientele (and, in turn, demand on our systems) continues to grow, we are confident that Go will continue to prove a reliable and performant choice for our critical systems.
The author wishes to thank Salil Gupta and Navin Gopaul for their many contributions to this post.