Big Data Analytics and the Cancer Moonshot
Recommendations for the White House Cancer Moonshot Task Force

Earlier this year, Vice President Biden gave me a homework assignment in his dining room.
He asked me, along with a few other data and analytics industry folks, to join him for a discussion about the significant role that data could play in doubling the pace of progress in cancer research and accelerating the discovery of treatments.
Now, you might be wondering, what did I stand to contribute to the Vice President’s Cancer Moonshot initiative? It’s a reasonable question, as cancer isn’t commonly thought of as a data problem, and I’m not a doctor or a medical researcher. But I have spent my career using data to improve outcomes that matter, including bringing cutting-edge analytics to Obama’s re-election campaign in 2012 and working to identify Americans who are most likely lacking health insurance.
It turns out that cancer is — increasingly — a big data problem.
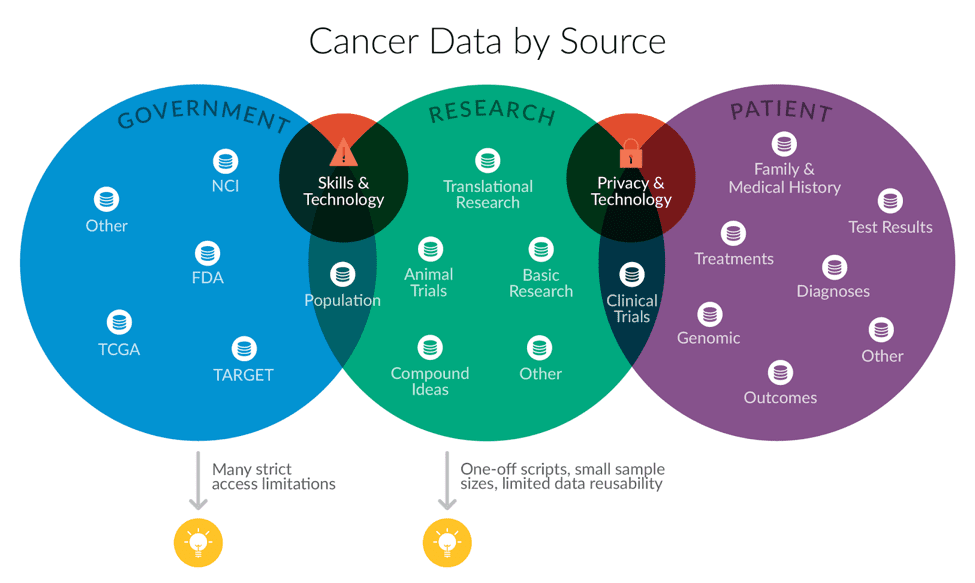
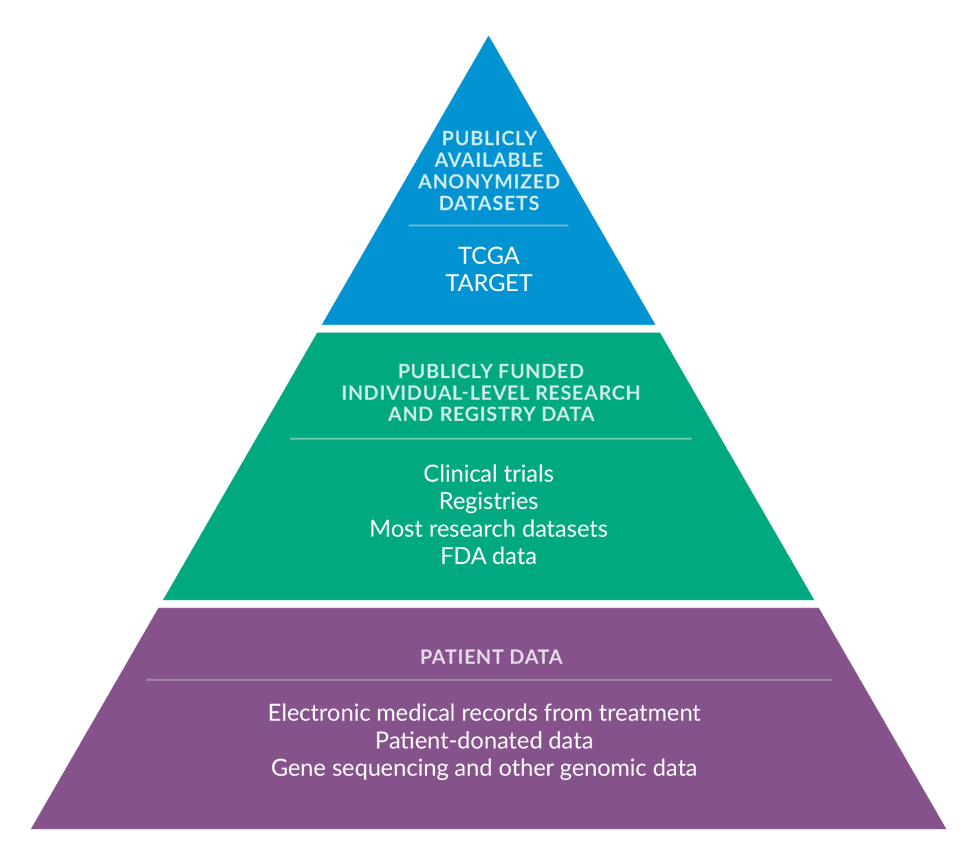
Gene sequencing, the critical tool for identifying cancer-causing genetic mutations, can produce over 100 gigabytes of data per person, which is roughly the amount of information that can be stored on your personal laptop. Concurrently, your hospital and insurance company are creating large amounts of important digital medical history. All that data could be used to better diagnose cancer patients (who’s sick?), improve precision delivery (what treatment should they receive?), and to identify new types of therapy (what new treatment will help this subset of patients?) — but right now, it’s not being used to its full potential. As cancer data collection technology improves, research centers need to learn how to store, aggregate, integrate, analyze, and interpret these vast data sets to improve research and delivery. And it’s not easy.
The Vice President’s charge to us was simple: “Tell me what I need to know. Tell me where we can make the most progress.”
So we got to work.
Together with a dedicated team at Civis Analytics, we worked to craft a set of data-centric policy recommendations for the Moonshot team. Over the course of four months, we talked to representatives from over 40 institutions, including pharmaceutical companies, academic research groups, insurers, legal teams, commercial and non-profit groups working on data systems, and survivors.
Then, we put together a report on what we learned. To read our recommendations, download the full report.
Good data science requires three big things: a comprehensive dataset to analyze, technology infrastructure to store and analyze that dataset, and skilled personnel to structure the data and carry out the analysis.
Right now, however, there are major systemic barriers that prevent the U.S. cancer research system from meeting these foundational requirements for good data science. As a result, there is a consensus within the community that the system is under-delivering on its potential for leveraging new data sources into better research. Our conversations identified challenges that range from complex technical problems, like how to efficiently store and analyze vast amounts of genetic sequencing data, to bureaucratic barriers around information sharing that slow innovation.
While it’s tempting to endorse a specific solution, like the newest subfield of research or a given institution, we recommend systemic reform in these three key areas — data sharing, data infrastructure and people and skills.
Despite its challenges, the industry has never been more hopeful about its future. Our conversations suggest that there is enormous promise in bringing together individual-level genomic and clinical data, and using data science techniques to uncover patterns. By supplementing existing basic and clinical research with data science, researchers can accelerate the development of new treatments.